All Articles
Article List
Intro
Throughout one’s life, a person can create a significant impact on the internet. Every like, every post, every text, and every single interaction has been tracked and recorded. This data is then used to target you in advertisements and marketing. This is the data known as your Digital Footprint. The internet’s reconstruction of who you are.
Now, given this Digital Footprint, you can find out a lot about a person. Things like how they speak, who their friends are, what they like or don’t like. It’s all there. Now, what if we take an LLM like ChatGPT and tell it to recreate you based on your digital life. Could it replicate your speech patterns and your thoughts? Could you possibly digitally bring someone back to life with their data on social media? Well, with today's technology rudimentary “digital cloning” is already possible. Using new fine-tuning capabilities with GPT-3.5, let’s see how far technology can take us.
The applications of this are endless. Think of a celebrity -- they could have a clone of themselves answer to fan mail. Or maybe you want to write an email in your own style. In general, a clone could potentially help get rid of the “AI” vibe that many LLMs give and allow you to generate content that makes it seem like you made it yourself. Perhaps you are a social media influencer and you want to automate updates on your twitter account, or a business that wants to create more personal emails to your customers. All of these things will be possible with this technology.
Fine Tuning
Fine tuning ChatGPT is relatively easy; just put in your data, and out pops a newly fine tuned model. Of course it is much more complicated under the hood, but we don't need to worry about that. This process behind this is very simple and can be summarized with this visual:

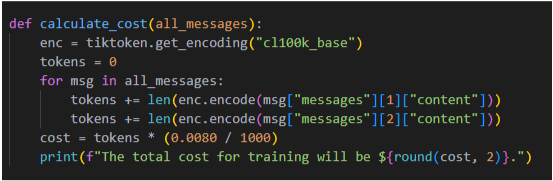
Essentially, you just create the data, upload it to OpenAI via their API (this example was done in Python), tell it to fine-tune using your data, and then run the fine-tuned model. Of course, this comes with a cost. For a couple hundred examples, I found that it wasn’t anymore than 1 dollar per fine tune. I used this handy function to calculate the cost of the fine-tune job, which required the tiktoken library to be installed.
Virtual Cloning
As mentioned in the introduction, a person’s digital life could be used to reconstruct themselves, however getting the data for one’s digital life can prove to be difficult. If you're a big tech company like Google or Amazon getting your hands on this data will probably be a piece of cake, however I don’t have those kinds of resources. Instead, we are going to be taking advantage of WhatsApp.
If you don’t already know, WhatsApp is a messaging app that is pretty popular. I use it to mainly converse with my family, especially those who aren’t in the US and have no other way of communicating overseas. Luckily, unlike social media, you can actually export your own conversations. This isn’t exactly ideal, since there is so much more data about one person online, but it is the best we have got. This is more or less a proof-of-concept anyway.
In order to fine-tune any model, you are going to need a very high quality dataset. Text messages? They are not high-quality in any shape or form. Consider this very simple hypothetical four message conversation:
Person1: Did you do what I asked?
Person2: Yea
Person1: Happy birthday!
Person2: thanks
Did that conversation make any sense to you? Probably not, because you are missing a lot of context. You may be asking yourself, “What did Person2 need to do?” Well, the issue is that real-life will influence what is said in the chat, which makes it hard to discern the meaning of some of the chats. And it gets even worse -- now consider this from the perspective of a machine. Unlike you or I, it can’t figure out that it was likely something IRL or that it just happened to be Person2's birthday. Instead, it will try to correlate whatever the Person1 asked to Person2’s birthday. Obviously there is no correlation but ChatGPT doesn’t know that! It will just try to learn off of what's given.
Hopefully that gave some insight into why datasets need to be squeaky clean for a fine-tune to work. In order to further drive this point home, lets see what happens if we just go in raw and give ChatGPT our un-cleaned dataset.
Going for it
To construct the dataset, I just took each message and told ChatGPT to predict what that message would be given the previous 10 messages. Here is what the input and output would look like:

This specific format is required for each input/output for OpenAI’s API to work. This stuff in light green is the input, and the text in red is what the output should be. This is repeated for each message in my WhatsApp conversations.
Using the process defined above, let's have a little conversation with my Clone.

It is certainly not great, but it is what we expected. At the very least, we can see some of the issues that arise out of bad data:
- The conversation is incoherent.
- The model hallucinates a ton. Where does coronavirus come from?
- The model somehow learned from other people. I have never fasted, thus I predict that that text was learned from my mother
However, despite these apparent pitfalls, at least the model did learn my style of writing somewhat. The last dialog especially is a lot like how I text, although the content is a bit wacky.
Dataset Cleaning
My initial ideas for dataset cleaning were as follows:
- Have the model “predict” what would come next in the data. Before, I would just tell it to complete the conversation. Now, I am telling it to predict the next text. This was in hopes that it wouldn’t get stuck trying to exactly fit the data, which we proved wasn’t perfect above.
- Choose only the best data points that give the most information about who I am. I did this via vector embeddings and chose the lines of text with similarities to “who, what, when, where, how,” in hopes that single worded and useless responses would not pollute the dataset.
- Better prompting. Going back to the basics, and create a prompt with an example so it hopefully will be less confused
After doing all three of these things, here is the conversation I end up with:

It's a little better, but honestly it is still pretty bad. There are some issues that still really stand out. Probably number one is hallucination. Despite some things in the prompt in order to prevent this, it still shines through a lot.
Again, like any issue with fine-tuning, it goes back to the data. Before, I was just telling ChatGPT to predict the next message given the last ten. This creates a lot of problems… Just take a look at this example

Do you see the issue here? Although this is perfectly valid text history, you can’t predict what I was going to ask my dad based on the previous information. This is due to the fact that I am assuming that the past five messages from a certain message will be relevant to that message. Evidently, that is not the case since text messages can be much more choppy especially when it's just a single quick question being asked. This means we need some way to filter out these chains.
To solve this, we can assume that one coherent conversation will have its texts occur around the same time. Let’s look at the same message chain with the timestamp along with each message.

Now it's obvious that there are three different conversations happening here despite them being right next to each other. Thus, in order for a text chain to be valid in the training data, each text must be near each other temporally.
In order to implement this in code, I arbitrarily chose 3 hours as the maximum time allowed between each message before it splits into a different text chain. Then, each of these splits are used in order to construct data for training. Here is what the previous example would look like now.

The message that used to be the output would now be used as an input for whatever next text-chain there is to come. Other than that, there were also more changes to the prompt. Here is what it looks like at this point (note that [HISTORY] would be replaced with the actual text conversation history)

I added some backstory, as well as a couple things in the beginning to try and prevent hallucinations, but it’s effectiveness varied. Since we are fine-tuning it, most issues are going to arise from the training data rather than the prompt itself.
Anyway, with all that out of the way, let’s talk to the third version of my clone!

Wow! It is MUCH more coherent than before, and it does behave somewhat like me. There is only one glaring issue that has been an issue throughout this entire journey: Hallucination.
I have never taken AP CSA. I don’t have a brother (or whatever a broßer is). I don’t play soccer. The issue is that ChatGPT is trying to fill in its missing information. Therefore, based on the data it already has it is trying to see what would be plausible. I like to code, therefore it makes sense I take AP CSA. It had a 50/50 chance with the brother/sister thing. High school boys do play soccer. If someone had no idea who I was, they might take this as an acceptable clone.
It seems like this issue has more to do with the amount of training data and the content of the training data. There simply is no mention of whether or not I have done these things, so ChatGPT has no chance to figure out what the real answer is based on the training data.
This basically comes down to how much of myself is really displayed in a WhatsApp chat. First, I don’t even use WhatsApp that much unless it's with my family. Second, since it is with only my family, information about myself never was really shown in the data. In that sense, the data is pretty biased.
Conclusion
With 2 dollars, a laptop, and some time I was able to make a prototype of a virtual clone. Now, imagine what you can do with your entire digital footprint. What kind of clone could be created if every single known thing about you online is crammed into an LLM? In a couple hundred years, or even less this could be possible. You may go from having your one digital clone to help you with menial tasks like answering emails, to creating a sort of pseudo-immortality by digitizing your entire personality.
It goes without saying that people have been trying to find a way to cheat death for centuries. That is where the more nefarious use-case of this kind of technology comes along. Your best friend dies. If you could, would you clone your best friend? Would you, just to have that last conversation even if it's just a superficial robot on the other end?