What is a Vector Embedding and why is it important?
In order to understand the power of vector embeddings, you need to first understand exactly what a vector means, or at least the very barebones definition. Let's take a trip back to geometry and consider a 2d plane. To describe a point on the plane, we can use the x and y axis. Thus, a point becomes any [x y]. Using the distance formula we can then calculate how close two points are. So, we can figure out that [1 1] is closer to [0 0] than [-3, -5]. The fact that we can describe points and figure out how close the points are from each other is what enables vector embeddings to be useful, which will be explained in more detail later. Although vectors have a much deeper meaning and are fundamentally different from simple points, for our purposes calling a vector a point on a graph is enough. It is also worth it to know that these points don’t have to be 2d, they can be 3d, 4d, or even 200d. Intuitively, vectors can be added, subtracted, or multiplied.
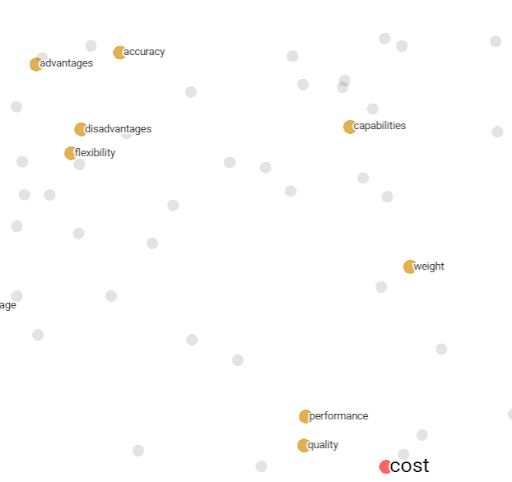
Vectors of words similar to "cost"
Now, how can these points help us? Essentially, the point of embeddings is to associate each word with a vector. Then, the embedding model’s job is to figure out how to arrange these points in such a way that the vectors representing the words contain a semantic meaning relative to other vectors.
This can be hard to wrap your head around. For it to make more sense, let’s take an example word: “run”. The vector that represents run will probably be geographically close to synonyms such as “sprint” or “dash”. It will also be close to words that may not exactly match, like “walk” or “jog”. But that is not the true power of embeddings. Like I said earlier, it can contain the meaning of the word as well. To show you this, let's see what happens when we subtract the vector for “run” with the vector for “fast.”
Vector of Run - Vector of Fast = Vector of Walk
Do you see what happened there? We basically “removed” a part of the meaning of the word in order to create another one. One attribute of running is that it is faster than walking, so when we remove the “fast” it just becomes “walk”. That is the true power of embeddings.
As you can imagine, the meanings that embeddings are able to capture greatly increase the potency of deep learning models. This is why most NLP models have an embedding layer in order to create these vector embeddings.
Vector Similarity
In terms of LLMs, vector embeddings have another great use. Imagine you have a document containing a bunch of important information about a company. You want to use an LLM, like ChatGPT, to query and ask questions about this data. The problem is that the document is 500 pages long and there are pretty much no LLMs that could possibly digest the entire document in one prompt. Instead, we need to find a way to extract only the relevant sentences that contain information about the query. We can then use those relevant sentences as data to give to the LLM rather than the entire document. This is where vector embeddings come into play.
Remember that vectors can be thought of as points in an n-dimensional space, thus we can find the distance between each vector. This means that if we can express a sentence as a vector, we can find the distance between two sentences in order to express how similar they are (normally using something called Cosine Similarity). Consider the aforementioned problem. In order to find which sentences have data that is relevant to the query, we can simply use embeddings in order to loop through each sentence in the document and find the “closest” sentences to the query. This works because sentences that have similar meaning to the query will likely have the answer to the query. This is called a Vector Search. Do note that the sentences should be more than 2-3 words long, because short sentences can lead to worse results with embeddings.
For example, if the query was “What is John’s favorite color,” and a story was given, any sentence containing “John” and a color (like red, blue, etc), will have the highest similarity score. Then, by using an LLM, we can distill this data into just the answer we want.
Vector Databases and how they work
Recall the fact that in order to perform a vector search, you need to basically find the closest vector to a certain point. This can be computationally expensive, especially if you have millions or even billions of vectors to sift through. Instead of searching through all of these vectors and measuring distance, you can use a special algorithm called Hierarchical Navigable Small Worlds (HNSW).
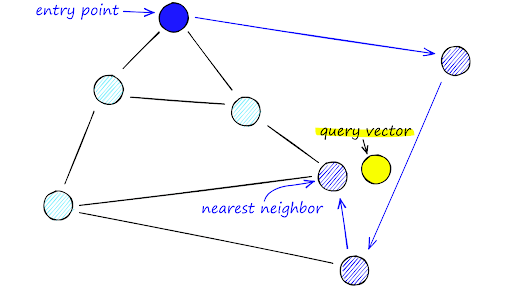
This algorithm has two parts: The hierarchy and the Navigable Small Worlds (NSW). NSW works by connecting each point (or vector) with their neighbors. Then, in order to find a vector, we start at a random entry point and search through each of the it's neighbors to find the neighbor closest to the target. Then, we use that neighbor and find the neighbor's neighbors and use the closest neighbor out of those. Essentially, as you traverse to more and more neighbors, you should get closer to the target. Once the current node you are on has neighbors that are all further away from the target than itself, you have found the nearest node to the target. This works pretty well, but can break down with extremely large amounts of data.
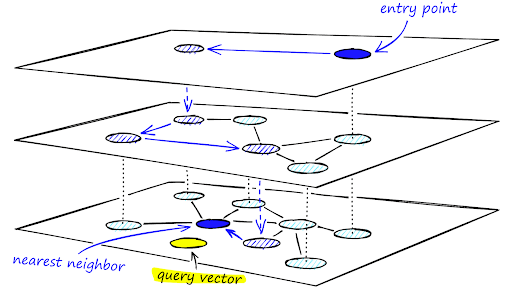
The second part, the hierarchy, is when you essentially take the points and remove a bunch of them. Then, as you go down the hierarchy, you add more and more points back in. Then, for each of these layers you use NSW, except once you find the closest point, you go down a layer. You keep on going until you reach the last layer, and the resulting point will be the nearest neighbor. This can be tricky to understand, so it is important to look at visualizations of it instead. Pinecone offers a great guide on it here: https://archive.pinecone.io/learn/hnsw/
HNSW is a pretty neat algorithm, and all that is left is an efficient way to actually store these vectors. Using SQL databases work great for this, which is what many of these Vector Databases actually use under the hood. You also won’t actually have to implement HNSW yourself -- the following table contains several of the best services and libraries for storing and querying vectors. Note: Most of these have free plans; the price displayed is the amount for the paid plan.
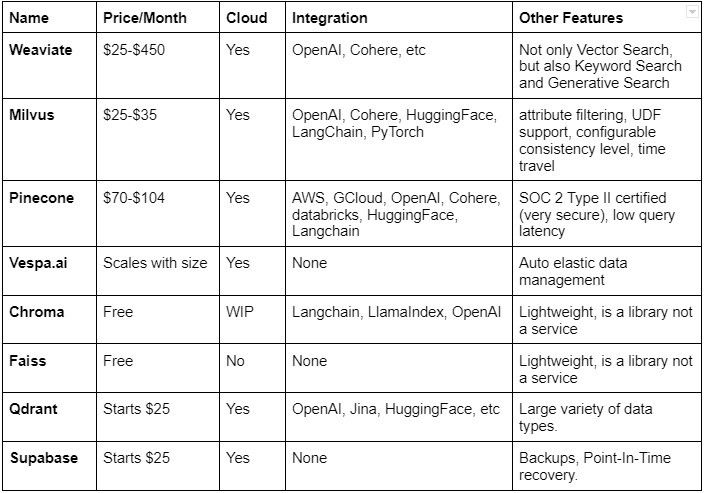
Although you could use any of these, in my opinion Pinecone is probably the best one. It is probably the most popular one, therefore having a lot of documentation and tutorials. Also, it has many integrations (the most on the list) and is on the cloud so you don’t need to worry about it. Chroma is also a great option if you want to host it locally, since it is open source and light weight. It also has probably the simplest API out of all of these.
Using a Vector Database to extend an LLM’s capabilities
In order to use a vector database, there are a couple things you need to do. First, you need to decide on the embedding model. For this example, I am going to be using OpenAI’s ada text embedding model. Then, you have to decide on the way you want to split up your data for embedding. For most cases, splitting them up by sentences is fine, but if you have a lot of data, splitting up by paragraph may be more beneficial in terms of speed. Finally, you can choose whichever database you would like to use. For this example we are going to use Chroma, but any of the above vector databases are suitable.
For the text, we are going to use the script of the first Harry Potter movie (Available here ). Here is what the data looks like:
import os
import pandas as pd
import chromadb
import openai
# Read the Dataset
dataset = pd.read_csv("HarryPotter.csv", delimiter=";")
print(dataset.head())
## OUTPUT
Character Sentence
0 Dumbledore I should've known that you would be here, Prof...
1 McGonagall Good evening, Professor Dumbledore.
2 McGonagall Are the rumors true, Albus?
3 Dumbledore I'm afraid so, professor.
4 Dubmledore The good and the bad.
For each sentence, let's convert them into an embedding and add them into the database. Chroma allows for OpenAI integration, so we don’t need to manually create the embeddings. To use Chroma, we first need to create a collection and specify the embedding function. Then, we may add the documents we want to embed. However, we only want to do this if the collection is empty. If it isn’t empty, that means that we already created the embeddings at an earlier time. This may take a while, since the dataset is relatively large.
One big issue that we are going to run into is the length of the sentences. Since this is a script, there are many one or two word sentences, which can lead to bad results when it comes to embeddings. Instead, we are going to “chunk” the sentences so that they have at least 100 characters.
# Specify the embedding function
embedding_func = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ.get("OPENAI_API_KEY"),
model_name="text-embedding-ada-002"
)
# Create the client and collection
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet", persist_directory="./chroma_database", ))
collection = client.get_or_create_collection("harrypotterscript", embedding_function=embedding_func)
if collection.count() == 0:
chunk = ""
idn = 0
# The sentences need to be chunked because short sentences don't work very well with Vector Search
for index, row in dataset.iterrows():
chunk += row["Sentence"] + " "
# Ensure that the chunk is at least 100 characters
if len(chunk) > 100:
collection.add(documents=chunk, ids=f"id{idn}")
chunk = ""
idn = 0
Finally, we can query our database.
similar = collection.query( query_texts=["Where does Harry Potter live?"], n_results=10, include=["documents"], ) ## Results ["Harry Potter, this is where I leave you. You're safe now. Good luck. You mean, You-Know-Who's out there, right now, in the forest? " # 'Can we find all this in London? If you know where to go. Ah, Hagrid! The usual, I presume? No, thanks, Tom. ', # 'Another Weasley! I know just what to do with you. Gryffindor! Harry Potter. Hmm... difficult, very difficult. ', # 'Harry Potter, you must leave. You are known to many creatures here. The forest is not safe at this time. ', # "Gringotts, the wizard bank. Ain't no safer place, not one. Except perhaps Hogwarts. Hagrid, what exactly are these things? ", # "I'm afraid Professor Dumbledore is not here. He received an urgent owl from the Ministry of Magic and left immediately for London. ", # "It's true then, what they're saying on the train. Harry Potter has come to Hogwarts. Harry Potter? This is Crabbe, and Goyle. ", # 'Mr. Harry Potter wishes to make a withdrawal. And does Mr. Harry Potter have his key? Oh, Wait a minute. ', # 'Anything you couldn\'t explain, when you were angry or scared? Dear Mr. Potter, We are pleased to inform you that you have been accepted at Hogwarts School of Witchcraft and Wizardry." ', "But Hagrid, we're not allowed to do magic away from Hogwarts. You know that. I do. But your cousin don't, do he? Eh? Off you go. "]
As you can see, it did produce some junk, but it did get the answer (Hogwarts). Now, in order to improve performance, we can use an LLM like ChatGPT to take this data as context and find an answer.
while 1:
query = input("Enter your query: ")
similar = collection.query(
query_texts=[query],
n_results=30,
include=["documents"],
)
context = ' '.join(similar['documents'][0])
prompt = f"Use the following context from the script of the Harry Potter movie to answer the question below.\n\n{context}\n\nQuestion: {query}\nAnswer: "
resp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful chatbot that helps people answer questions about the Harry Potter movie."},
{"role": "user", "content": prompt},
]
)
msg = resp["choices"][0]["message"]["content"]
print(msg)
## Results
Enter your query: Where does Harry Potter live?
Answer: Harry Potter lives at Hogwarts School of Witchcraft and Wizardry.
Enter your query: What is the name of headmaster of Hogwarts?
Answer: The name of the headmaster of Hogwarts is Albus Dumbledore.
Conclusion
Vector embeddings are an amazing technology. They have been around for a while, but with the creation of large language models embeddings got a whole new usage. Not only can you extend a model’s knowledge, but you can also be assured that what the model is saying isn’t misinformation or hallucination, because you are supplying it with the data. All the model is doing is reorganizing it to answer the question. I think that that is more important than ever, because for more sensitive topics, such as medicine and law, misinformation can be really bad. Instead, you can supply your own trustworthy knowledge. With that being said, embeddings help unlock the true potential of LLMs.